- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
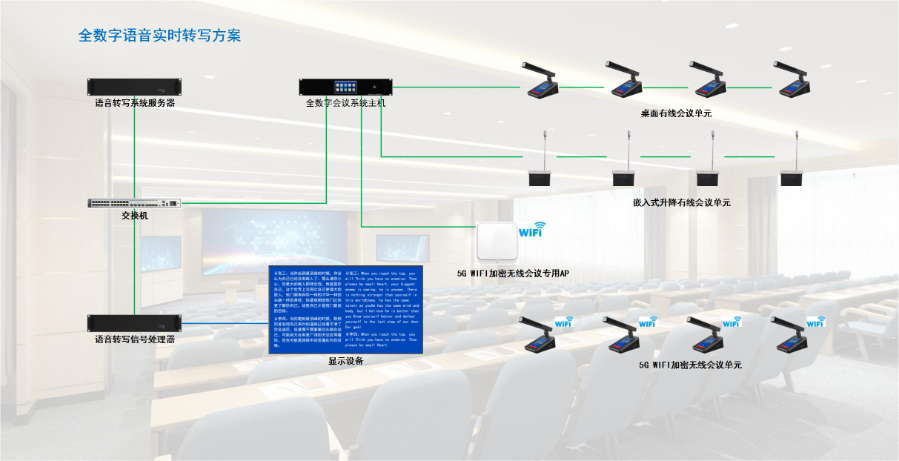
针对教育行业特殊需求,语音转写产品推出定制化服务。对 K12 学校,提供 “课堂转写 + 教学管理” 一体化方案,转写内容可自动关联课程表,每节课的转写文档按 “年级 - 学科 - 课时” 分类存储,教师可通过后台查看学生标注的疑问点,针对性调整教学;对高等院校,开发 “学术讲座转写” 专项功能,支持识别专业术语(如物理领域 “量子纠缠”、历史领域 “君主专制”),自动生成参考文献格式标注,方便学生整理学术资料,同时支持多语言讲座转写,满足国际交流课程需求;对培训机构,提供 “课程复盘” 功能,将授课语音转写后,系统自动分析教学节奏、知识点分布,为教师优化课程设计提供数据支持。语音转写的智能排版功能为会议记录自动分区,如“参会人-议题-行动项”。长沙智能翻译语音转写系统

智能语音转写对信息传播产生了深远的影响.在过去,信息的传播往往依赖于文字的书写和印刷,传播速度受到一定限制.而语音转写技术的出现,打破了这一局限.它使得语音信息能够快速、准确地转化为文字,进而通过各种网络平台进行普遍传播.例如,新闻发布会、学术讲座等内容可以通过语音转写后,在社交媒体上迅速传播,让更多人能够及时获取信息.同时,语音转写也为信息的存档和检索提供了便利.大量的语音资料通过转写变成文字后,可以进行高效的分类和搜索,人们能够快速找到所需的信息.这种高效的信息传播和检索方式,进一步促进了知识的传播和交流,推动了文化的繁荣发展.北京全数字语音转写软件老年用户友好版语音转写放大按钮与字体,支持方言语音控制,降低使用门槛。
语音转写产品针对老年用户,进行界面与功能的友好化改造,降低使用门槛。在界面设计上,采用 “大字体、高对比度” 显示,按钮尺寸放大 30%,文字颜色选用黑底黄字、白底蓝字等醒目配色,避免视觉疲劳;在操作流程上,简化功能入口,将 “实时转写”“音频导入”“文档导出” 等重心功能放在首页,支持 “一步操作”,例如点击 “开始转写” 后自动开启降噪,无需额外设置;在语音交互上,强化语音控制功能,老年用户可通过 “打开转写”“保存文件”“帮助中心” 等语音指令完成操作,同时支持方言语音控制,适配老年用户口音习惯;此外,产品还内置 “老年用户专属客服”,提供语音导航的人工服务,手把手指导操作,让老年用户也能轻松使用语音转写服务。
语音转写产品针对儿童教育场景,开发趣味化、引导式转写功能,适配儿童学习习惯。在亲子阅读场景,产品支持 “绘本语音转写 + 互动答问”,家长朗读绘本时,系统实时转写文字并同步显示绘本插图,转写完成后自动生成与内容相关的趣味问题(如 “小熊现在去了哪里呀”),帮助儿童加深内容理解;在口语练习场景,产品内置儿童发音评测模块,转写儿童英语、语文口语表达时,同步分析发音准确度、语调流畅度,生成可视化评分报告,标注 “发音不准词汇” 并提供标准读音示范,助力儿童提升口语能力;此外,产品还支持家长管控功能,可设置每日使用时长、内容过滤规则,避免儿童接触不适宜内容,打造安全的学习辅助环境。语音转写在会议纪要整理方面表现出色,能快速生成详细的文字记录。
语音转写产品不能完成语音到文字的基础转化,更具备强大的智能辅助能力,为用户提供超越基础功能的增值价值,这是其区别于传统工具的关键优点。在内容提炼上,可自动提取转写文本中的关键数据、重心观点与待办事项,生成结构化摘要,例如会议转写后自动梳理 “决策事项 - 责任人 - 截止时间” 清单,省去人工筛选时间;在内容优化上,内置 AI 编辑功能,能识别文本中的语法错误、冗余表述,提供优化建议,如将口语化的 “大概、可能” 调整为更严谨的书面语,助力提升文档专业性;在知识关联上,可自动链接转写内容中的专业术语、人名地名,跳转至百科解释或相关资料,例如转写中出现 “量子计算” 时,点击即可查看基础概念,辅助用户理解陌生内容,让转写从 “记录工具” 升级为 “知识处理助手”。语音转写支持多格式音频导入,包括MP3、WAV、AAC等主流音频文件类型。长沙多语言识别语音转写故障排除
专业的语音转写系统可识别多种语言,满足不同用户的语言转写需求。长沙智能翻译语音转写系统
在当今社会,司法公开是法治建设的重要内容.公众对司法审判的知情权和监督权越来越受到重视.智能语音转写应用为司法公开提供了有力的技术支持.庭审记录的文字版可以通过法院官方网站、司法公开平台等渠道向公众公开,让公众能够及时了解案件的审理过程.这使得司法审判不再是一个神秘的过程,公众可以清楚地看到案件的证据展示、当事人的陈述和辩论等环节.这增强了司法的透明度和公信力,使公众对司法审判有更直观的认识.同时,对于当事人和社会监督者来说,他们可以通过查阅庭审记录来监督司法审判的公正性,促进司法权力的正确行使,让司法更加公正、透明.长沙智能翻译语音转写系统

语音转写软件的精细性使其在众多领域备受青睐,这得益于先进的技术支撑.其精细识别依赖复杂的声学和语言模型分析.声学模型能细致分析和建模语音的声学特征,无论语音的音色、语调、音量如何变化,都能精细捕捉细节.语言模型基于大规模语料库训练,能理解不同语境下的语义信息,准确将语音转化为文字.在实际应用中,对于各种口音,如不同地区方言或特定文化背景下的口音,软件都能较好识别关键信息.面对连读、弱读等复杂语音现象,也能通过智能算法处理,还原语义.比如在快速对话场景下,软件能通过音素分析准确识别连读内容.其高准确的识别结果减少了人工校对工作量,让用户能更专注于信息处理和分析.语音转写与AI编辑结合,能修正语法...
- 广州多角色语音转写有什么功能 2026-02-07
- 智能翻译语音转写有什么功能 2026-02-07
- 角色分离语音转写云平台 2026-02-07
- 南京多语言识别语音转写软件 2026-02-07
- 上海法院语音转写系统 2026-02-07
- 南京角色分离语音转写售后 2026-02-07
- 多语种识别语音转写故障排除 2026-02-07
- AI智能语音转写有什么功能 2026-02-06
- 广州多角色语音转写同时翻译 2026-02-06
- 南京全数字语音转写同时转写 2026-02-06


- 广州角色分离语音转写软件 2026-02-06
- 北京语音转写故障排除 2026-02-06
- 长沙法院语音转写 2026-02-06
- 实时语音转写字幕 2026-02-06
- 广州智能语音转写软件系统 2026-02-06
- 南京自动记录语音转写哪家好 2026-02-05




- 上海法院语音转写系统 02-07
- 南京角色分离语音转写售后 02-07
- 多语种识别语音转写故障排除 02-07
- AI智能语音转写有什么功能 02-06
- 广州多角色语音转写同时翻译 02-06
- 南京全数字语音转写同时转写 02-06
- 广州AI智能语音转写同时翻译 02-06
- 上海多语种识别语音转写故障排除 02-06
- 南京国产化语音转写报价 02-06
- 多语种识别语音转写 02-06